The networking part of Openstack provides several models for the L2 networks to be used as L2 tenant broadcast domains. An overlay network can be used to separate the MAC addresses and „vlans“ of the tenant networks from the transport layer network.
Openstack neutron in Havana supports two overlay network technologies, GRE and VXLAN. VXLAN is my preferred solution, because it provides more entropie on the receiving NIC, which results in a higher performance, because multiple CPU cores are used to process ingress packets.
In this article I’ll show the implementation of VXLAN on three nodes. Two nodes are used as compute hosts, one node is used as the network node. On the network node (NN) several Neutron agents are running:
- L3 agent: This one is responsible to build tenant routers using Linux network namespaces
- DHCP agent: This one is responsible to build DHCP servers for tenant networks using Linux network namespaces
- L2 (OVS) agent: This one configures and provisions the OVS
The Neutron metadata services is also deployed to provide cloudinit support for started VMs.
On the compute nodes (CN), only the L2 (OVS) agent is necessary.
A typical Openstack deployment is using one instance of the OVS, br-int, as the point to connect all VMs, DHCP servers and the „non default gateway“ side of all routers. br-int is using classic Vlans to separate the broadcast domains.
br-tun is a second OVS instance, and is used to provide the VXLAN function. br-tun is connected to br-int via an internal link. This links is a trunking port, it is using dot1q tagging to transport vlan ids-
When configuring Openstack Neutron (Havana not using ML2 ) I recommend to change the value of the tunnel ids in the neutron config to:
tunnel_id_ranges = 65537:69999
Changing this from the default values, which are below 4096, has the great advantage, that it easy to distinguish vlans ids from vxlan tunnel ids. This helps to understand the Openflow rules provisioned by neutron on br-tun. Why using 65537 as the first tunnel id? Well, 65537 in hex is 0x10001 and the OVS shows tunnel ids as hex values. It’s easy to read….
When using Openstack Icehouse on Ubuntu with ML2, the openvswitch plugin is not longer used. Any openvswitch config must be put in the ml2 plugin config file, using the section „ovs“.
[ml2] type_drivers = vxlan,local tenant_network_types = vxlan mechanism_drivers = openvswitch [ml2_type_vxlan] vni_ranges = 65537:69999 [ml2_type_gre] tunnel_id_ranges = 32769:34000 [ovs] local_ip = <set IP for the tunnelinterface> tunnel_type = vxlan tunnel_bridge = br-tun integration_bridge = br-int tunnel_id_ranges = 65537:69999 tenant_network_type = vxlan enable_tunneling = true [agent] root_helper = sudo neutron-rootwrap /etc/neutron/rootwrap.conf tunnel_types = vxlan vxlan_udp_port = 4789 l2_population = False [securitygroup] enable_security_group = True firewall_driver = neutron.agent.linux.iptables_firewall.OVSHybridIptablesFirewallDriver
My recommendation is, to use different ranges for vlans, vxlan tunnelid’s (vni’s) and gre id’s.
This leads to the following setup as shown in the drawing (without showing the second compute node), which is using eth1 as the IP interface to transport the VXLAN traffic and br-ex to attach the routers to the public address pool 198.18.1.0/24.
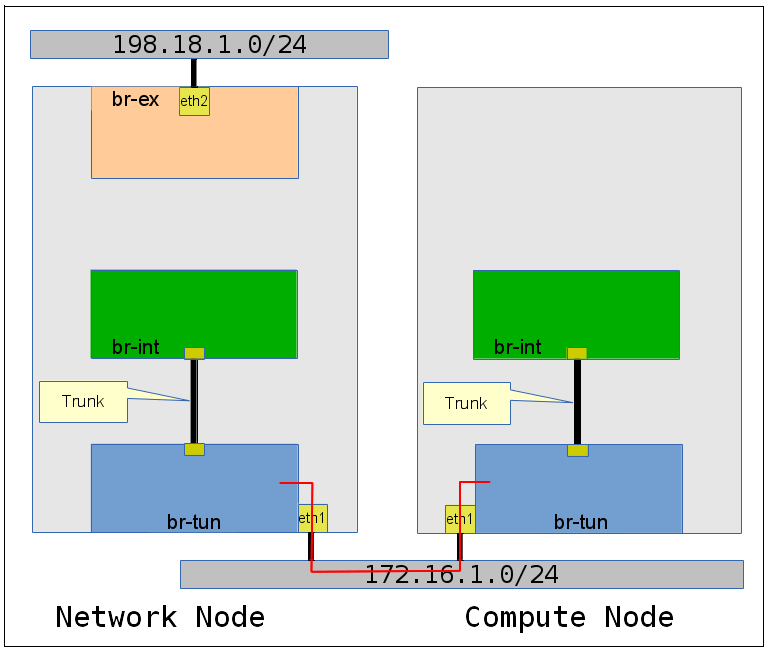
On the VXLAN transport network it is very important to use jumbo frames. If you choose 1600 instead of the default 1500 you’re on the safe side. The VXLAN tunnel overlay requires an additional UDP header on top of a full sized ip packet. Without jumbo frames the performance of GRE and VXLAN overlays drop to less than 100 MBit/s – instead of using 10 GBit/s and more. This performance drop is caused by the required packet fragmentation and defragmentation CPU processing needed on the sending and receiving side of the tunnel.
br-tun Openflow rules
Now we take a look at br-tun. First we get the ports using the command ovs-ofctl show br-tun and a following grep to filter unnecessary output.
ovs-ofctl show br-tun | grep -v -E "REPLY|n_tables|capabilities:|actions:|config:|state:" 1(patch-int): addr:6e:72:61:71:d9:02 speed: 0 Mbps now, 0 Mbps max 2(vxlan-2): addr:ee:bb:80:d1:90:0a speed: 0 Mbps now, 0 Mbps max 3(vxlan-3): addr:f2:be:77:6f:66:e6 speed: 0 Mbps now, 0 Mbps max LOCAL(br-tun): addr:1e:8c:fc:76:b2:4b speed: 0 Mbps now, 0 Mbps max
br-tun has three ports:
- port 1 is the connection to br-int
- port 2 is the connection to compute node 1
- port 2 is the connection to compute node 2
- port LOCAL is an internal OVS port
The openflow rules can be shown using the command ovs-ofctl dump-flows br-tun:
ovs-ofctl dump-flows br-tun
NXST_FLOW reply (xid=0x4):
cookie=0x0, duration=1806.214s, table=0, n_packets=0, n_bytes=0, idle_age=1806, priority=1,in_port=1 actions=resubmit(,1)
cookie=0x0, duration=1044.587s, table=0, n_packets=0, n_bytes=0, idle_age=1044, priority=1,in_port=3 actions=resubmit(,3)
cookie=0x0, duration=1320.063s, table=0, n_packets=0, n_bytes=0, idle_age=1320, priority=1,in_port=2 actions=resubmit(,3)
cookie=0x0, duration=1806.18s, table=0, n_packets=0, n_bytes=0, idle_age=1806, priority=0 actions=drop
cookie=0x0, duration=1806.114s, table=1, n_packets=0, n_bytes=0, idle_age=1806, priority=0,dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,21)
cookie=0x0, duration=1806.146s, table=1, n_packets=0, n_bytes=0, idle_age=1806, priority=0,dl_dst=00:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,20)
cookie=0x0, duration=1806.082s, table=2, n_packets=0, n_bytes=0, idle_age=1806, priority=0 actions=drop
cookie=0x0, duration=1806.049s, table=3, n_packets=0, n_bytes=0, idle_age=1806, priority=0 actions=drop
cookie=0x0, duration=1806.017s, table=10, n_packets=0, n_bytes=0, idle_age=1806, priority=1
actions=learn(table=20,hard_timeout=300,priority=1,
NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],
load:0->NXM_OF_VLAN_TCI[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],
output:NXM_OF_IN_PORT[]),output:1
cookie=0x0, duration=1805.985s, table=20, n_packets=0, n_bytes=0, idle_age=1805, priority=0 actions=resubmit(,21)
cookie=0x0, duration=1805.953s, table=21, n_packets=0, n_bytes=0, idle_age=1805, priority=0 actions=drop
The Openflow rules shown, use different tables. table 0 is processed as the first one. Each table has rules with different priorities, the rules with the highest priority are checked first. At this stage, the rules do not make much sense.
The output below shows the checks done for an unicast packet entering from port=1.
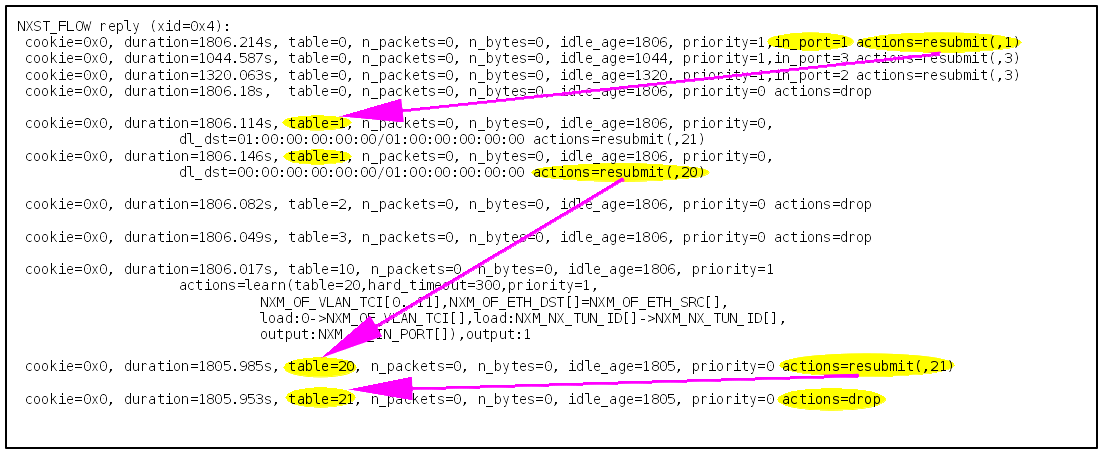
Openflow rules after the installation or br-tun
As we have seen above, port 1 is the port to br-int. Any packet entering port 1 is resubmitted to table 1. The first rule of table 1 checks if the packet is a multicast or broadcast ethernet packet. As we have an unicast packet, the rule does not match. The next rule is true for all unicast ethernet packets, so the packet is resubmitted to table 20. We have at this stage only one rule in table 20 and the action is resubmit to table 21. In table 21 the packet is dropped, because the action is drop.
At this stage, br-tun drops all traffic entering on one of the three ports. This is fine, as we did not configure anything as a tenant within Openstack.
Add a router, one network and one subnet.
Now it ’s time to add networking from the tenant’s perspective within Openstack. The tasks are:
- Add a router
- Connect the router to the public network by setting a default gateway
- Add a network as a broadcast domain
- Add a subnet to the network. Within Openstack a subnet is an IP network.
The router is deployed as a Linux network namespace on the network node, as soon as there is an interfaces connected to the router. Do not use any agent stuff without enabled network namespaces. The first interface we added to the router in our example is the default gateway.
VXLAN to Vlan mapping
After creating the tenant network, the Openflow rules on the nodes for br-tun looks like:

Openflow rules on br-int after creating one tenant network
Two rules have been added:
- In Openflow table 3 a rule has been added to map the globally unique tunnel_id to the vlan_id, which has only node local scope. Any traffic which matches this rule is forwarded to Openflow table 10. The action of the first rule of Openflow table 10 has two actions. The first one performs MAC learning and inserts the learned MAC addresses together with a vlan_id to tunnel_id mapping and the egress vlxlan port to Openflow table 20. Openflow table 20 is used for egress traffic. The second action is to output the traffic to Openflow port 1, which is the port to br-int.
- In Openflow table 21 a rule has been added to map the local vlan_id to the global tunnel_id. This rule is only used for broadcast, multicast or unknown unicast traffic. Unknown unicast traffic is flooded by default. These packets are sent by default to ALL nodes in the vxlan mesh. This is a very bad behaviour. The network implementation does not support VLAN pruning.
Start a VM on compute node 1
After starting a VM on compute node 1, the Openflow table on br-tun looks like.

Openflow rules on the compute node after learning the MAC addresses of the DHCP server and the router
Openflow table 20 contains two new rules, which have been inserted by the learning action of the Openflow rule in table 10. The two new rules contain the MAC addresses of the router and the DHCP server. Port 2 is the VXLAN tunnel to Compute node 1.
On the network node, a similar learned Openflow rule appears in table 20. This rule contains the MAC address of the VM.
Unicast packet transmission from the VM on the compute node
When the started VM on the compute node transmits a packet with the destination „router MAC address“, the walk through the Openflow rules on br-tun looks like:
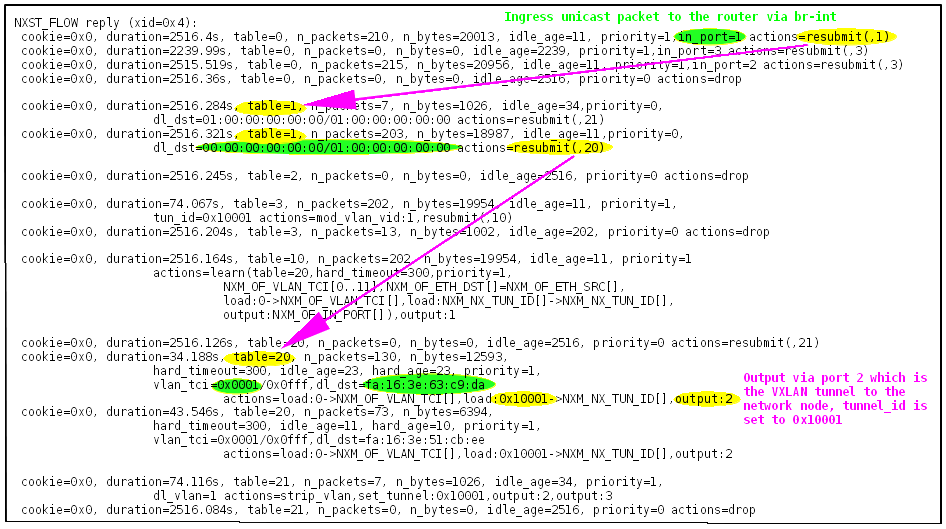
Openflow rule walktrough when the VM transmits an unicast packet to the router MAC
- The packet enters br-tun on port 1, which is the connection to br-int. The first prio=1 rule of table 0 matches and the packet is resubmitted to table 1.
- In table 1 the second rule matches, because the packet is an unicast packet. The packet is resubmitted to table 20, which is the table for learned MAC addresses.
- In table 20 the first rule of priority=1 matches, because of the destination MAC address. The action sets the tunnel_id to 0x10001, sets the vlan_id to zero (which removes the vlan dot1q tag) and transmits the packet through port 2, which is the vxlan virtual port to the network node.
Any packet entering table 20, which does NOT match any of the rules with priority=1 is processed by the priority=0 rules of table 20 and resubmitted to table 21. The prio=1 rule in table 21 „floods“ the packet to ALL nodes in the mesh using unicast.
Packet sent to the VM
When the started VM on the compute node receives a packet, the walk through the Openflow rules on br-tun looks like:
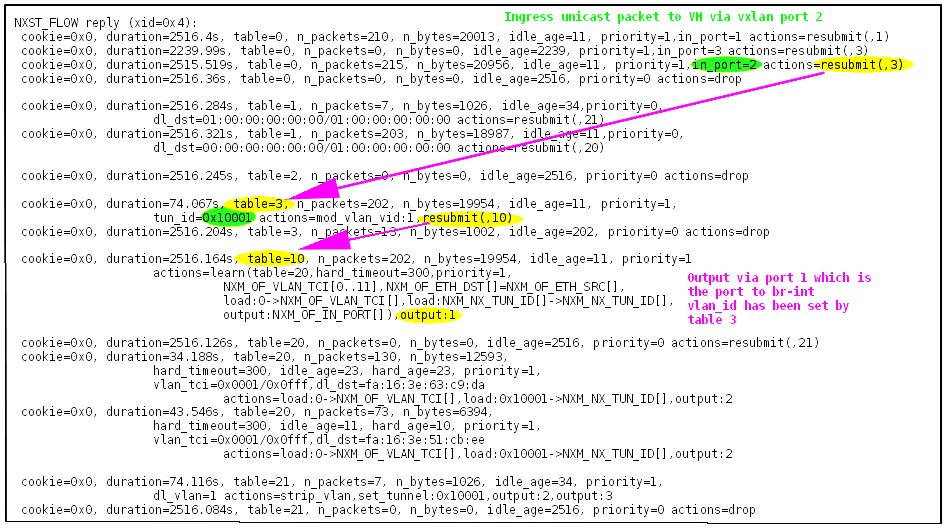
Openflow rule walkthrough when a packet is transmitted to the VM
- The packet enters br-tun on port 2, which is the vxlan connection to the network node. The third prio=1 rule of table 0 matches and the packet is resubmitted to table 3.
- In table 3 the first rule matches, because the tunnel_id is 0x10001. The vlan_id of the packet is set to 1 (which is the local vlan_id for the global tunnel_id). The packet is resubmitted to table 10
- In table 10 the only rule is processed. This rule has two actions. Action one performs MAC learning. If the MAC address of the sender is not in the MAC learning Openflow table 20, it is added to the table including the mapping tunnel_id to vlan_id. The second action is to transmit the packet out of port 1, which is the port to br-int.
Conclusion
The implementation of the vxlan mesh in Openstack Havana is straight forward. It provides a working L2 connectivity when running IPV4. Anyhow, it misses features, which are delivered even with cheap hardware switches. These are:
- no Vlan pruning. It is quite simple to overflow the whole infrastructure using broadcast traffic (or multicast traffic). Traffic replication for target systems reachable only via vxlan tunnels, is done on the egress Openvswitch. This does not scale in large environments (>> 30 nodes)
- no IGMP and MLDv2 snooping. Together with the missing Vlan pruning, this makes it impossible to run applications which require IP multicast.
To optimize the traffic handling other features must be implemented to allow scaling to high node numbers.
- MAC preprovisioning (addressed by ML2 and/or Openstack Icehouse) to avoid flooding of traffic
- ARP preprovisioning to avoid flooding of traffic
- preprovisioned IPV6 neighbor entries to avoid flooding of traffic
- use a multicast address to flood traffic (addressed by Openstack Icehouse), but still no Vlan pruning
- support IGMP and MLDv2 snooping on the OVS
- support the mapping of multicast traffic in the overlay network to PIM-SSM in the underlay network